随着 AI SaaS 与大模型应用快速发展,越来越多企业开始采用:
多云 + Kubernetes + GPU 的 AI 基础设施架构
原因很简单:
- 单云成本高
- 单点风险大
- 全球部署受限
但多云环境下,一个核心问题出现了:
❗ 如何高效调度 AI 容器与 GPU 资源?
本文将系统讲解:
多云 AI 容器调度优化方案,从架构设计到实战策略
👉 建议先阅读基础文章:
一、为什么需要多云 AI 架构?
企业在 AI 部署中常遇到:
成本问题
- AWS GPU 昂贵
- GCP GPU 资源有限
- 阿里云价格更低
全球部署问题
- AWS 全球强
- 阿里云亚洲强
- 华为云欧洲强
稳定性问题
- 单云故障风险
👉 因此:
多云成为企业级 AI 架构的必然选择
二、多云 AI 调度的核心挑战
1️⃣ GPU 资源分散
不同云:
- GPU 型号不同
- 价格不同
2️⃣ 网络复杂
- 跨云通信延迟高
- 数据同步困难
3️⃣ 调度困难
Kubernetes 默认:
👉 不支持跨云调度
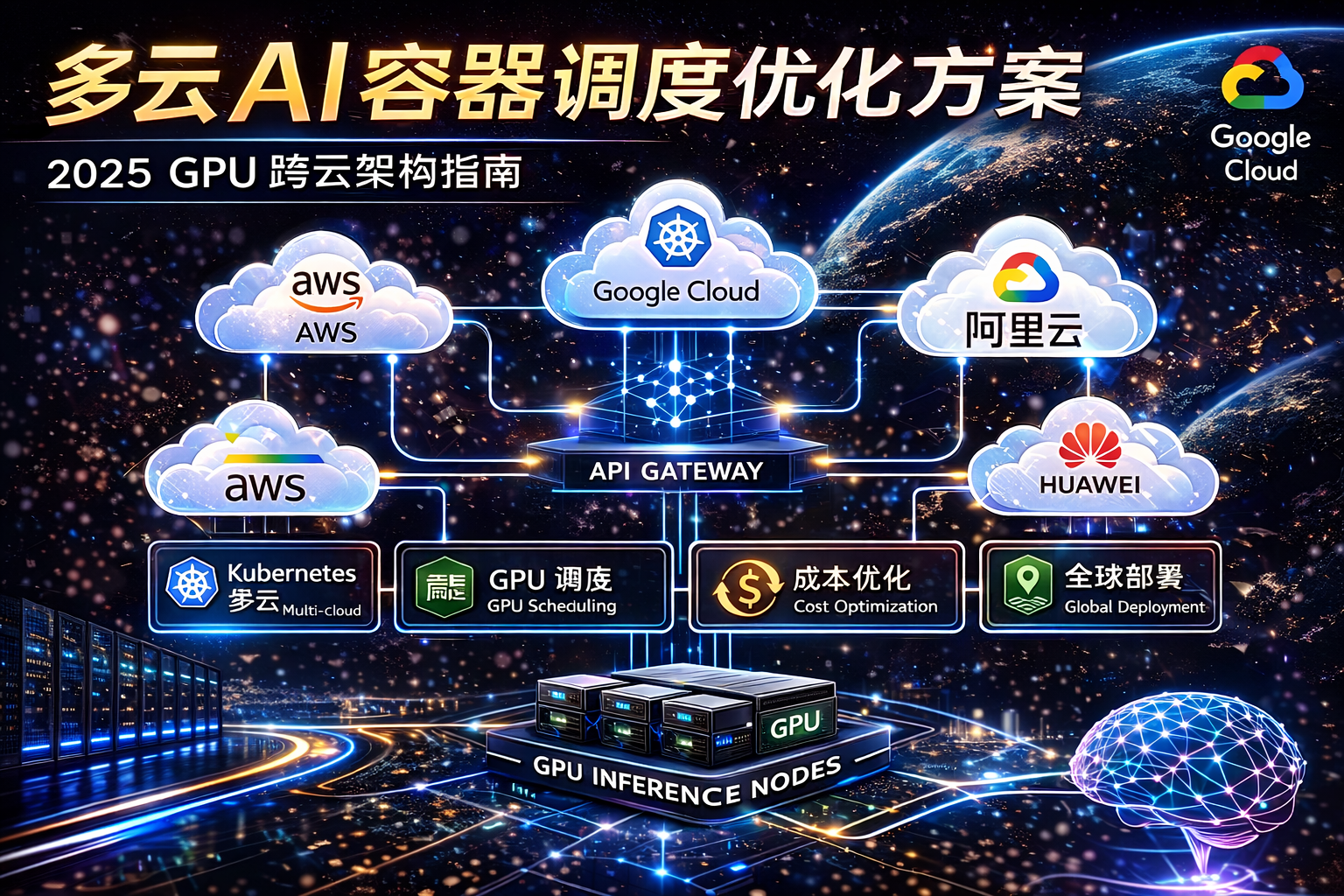
三、多云 AI 架构设计(核心)
推荐架构
用户
↓
Global Accelerator / CDN
↓
调度层(Multi-Cloud Scheduler)
↓
Kubernetes 集群(多云)
↓
GPU Node Pool
↓
推理服务
云厂商组合
推荐:
- AWS(全球)
- GCP(AI生态)
- 阿里云(亚洲)
- 华为云(欧洲)
👉 GPU 成本参考:
👉 《多云 GPU 成本对比:AWS / 阿里云 / 华为云》
四、多云容器调度方案
方案一:多集群 Kubernetes
每个云:
- 独立 Kubernetes
通过:
- API 调度
- 统一网关
优点:
✔ 简单
✔ 稳定
缺点:
❌ 统一调度复杂
方案二:Kubernetes Federation
K8s 官方方案:
👉 https://kubernetes.io/docs/concepts/cluster-administration/federation/
优点:
✔ 跨集群调度
缺点:
❌ 复杂
❌ 运维成本高
方案三:服务网格(推荐)
使用:
- Istio
- Linkerd
实现:
- 跨云服务通信
- 流量调度
👉 官方:
方案四:自定义调度层(企业推荐)
构建:
👉 AI 调度平台
根据:
- GPU价格
- 延迟
- 负载
动态调度。
五、GPU 调度优化策略(重点)
1️⃣ 按成本调度
示例:
- 低成本 → 阿里云
- 高性能 → AWS
2️⃣ 按延迟调度
用户:
- 欧洲 → 华为云
- 东南亚 → 阿里云
👉 延迟优化:
3️⃣ 按负载调度
- 高峰 → 扩容 AWS
- 低峰 → 切换低价云
4️⃣ 按模型调度
- 小模型 → L4
- 大模型 → A100 / H100
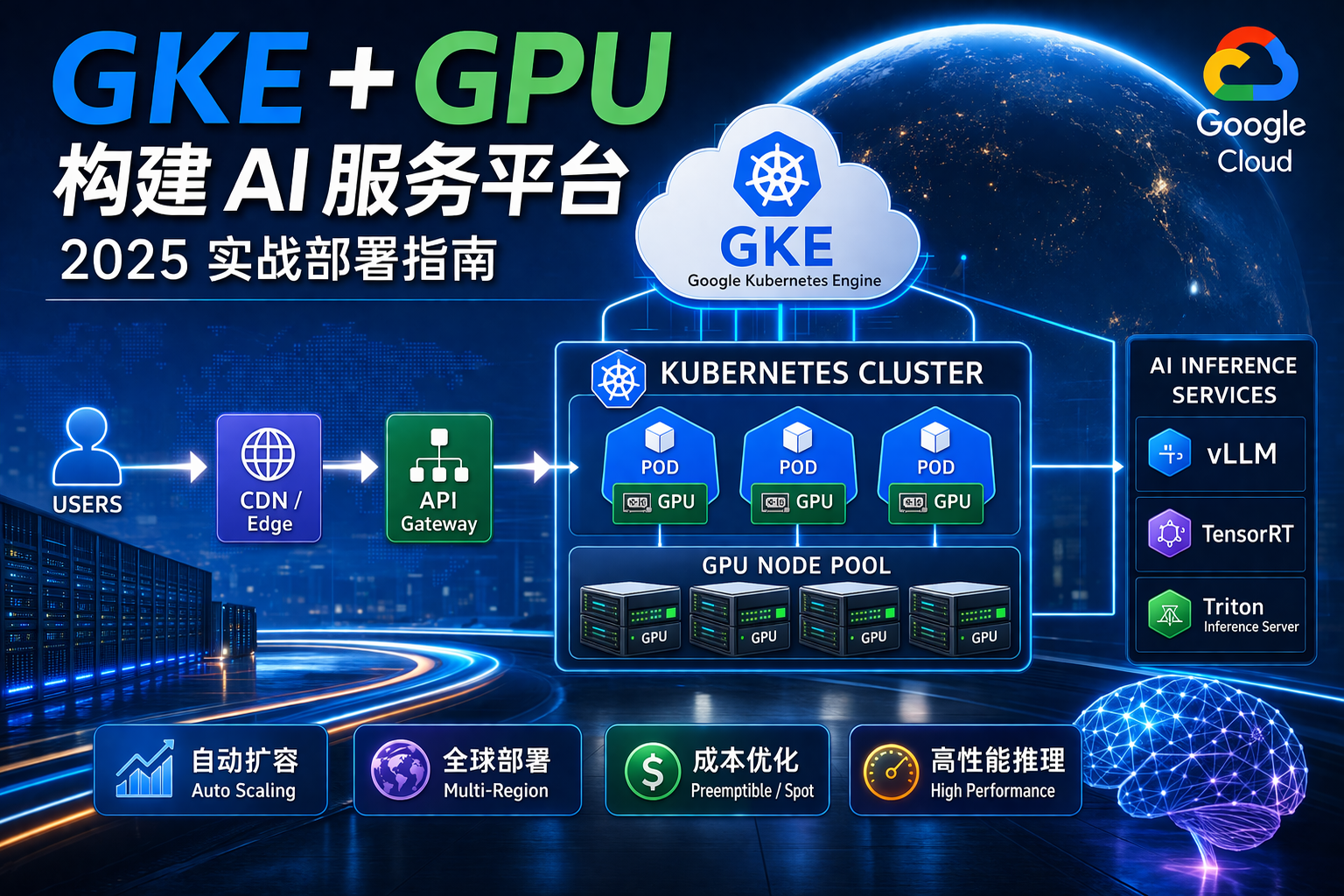
六、自动扩容(多云)
结合:
- HPA
- Cluster Autoscaler
- 多云调度
👉 推荐阅读:
七、网络优化(关键)
1️⃣ 跨云互联
- VPN
- 专线
2️⃣ 全球加速
- CDN
- Anycast
3️⃣ 边缘节点
- Edge Computing
八、企业级最佳实践
✔ 多区域部署
✔ 多云 GPU 调度
✔ 自动扩容
✔ API 网关统一入口
✔ 服务网格
九、完整多云 AI 架构
用户
↓
CDN / Global Accelerator
↓
API Gateway
↓
多云调度层
↓
AWS / GCP / 阿里云 / 华为云
↓
GPU 推理服务
📌 总结
多云 AI 架构的核心在于:
调度能力 + 成本控制 + 全球部署
谁能做到:
✔ 智能调度
✔ 成本最优
✔ 延迟最低
谁就能赢。
🚀 推荐方案
如果你希望:
- 构建 AI SaaS
- 全球部署 AI
- 降低 GPU 成本
👉 推荐参考: