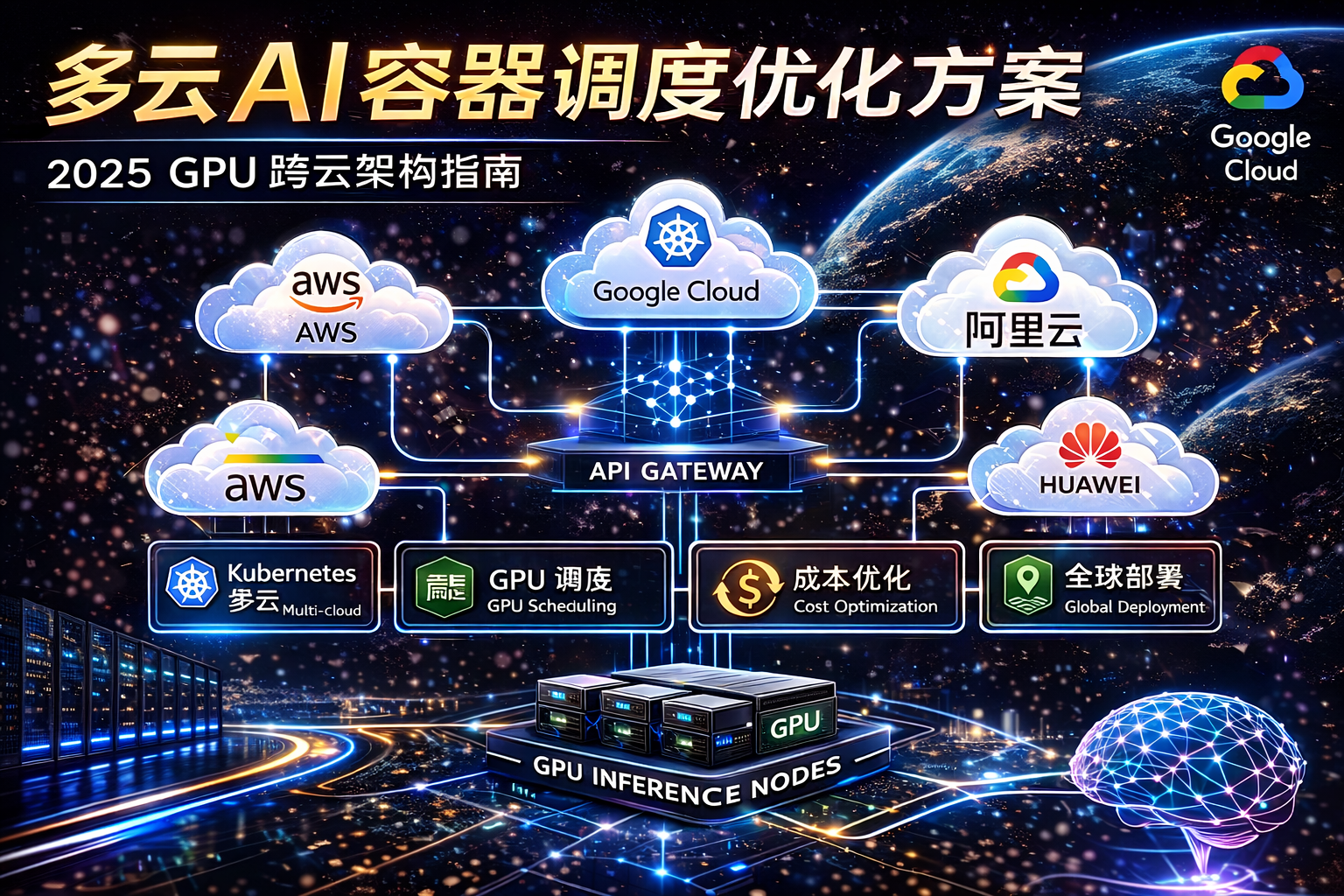
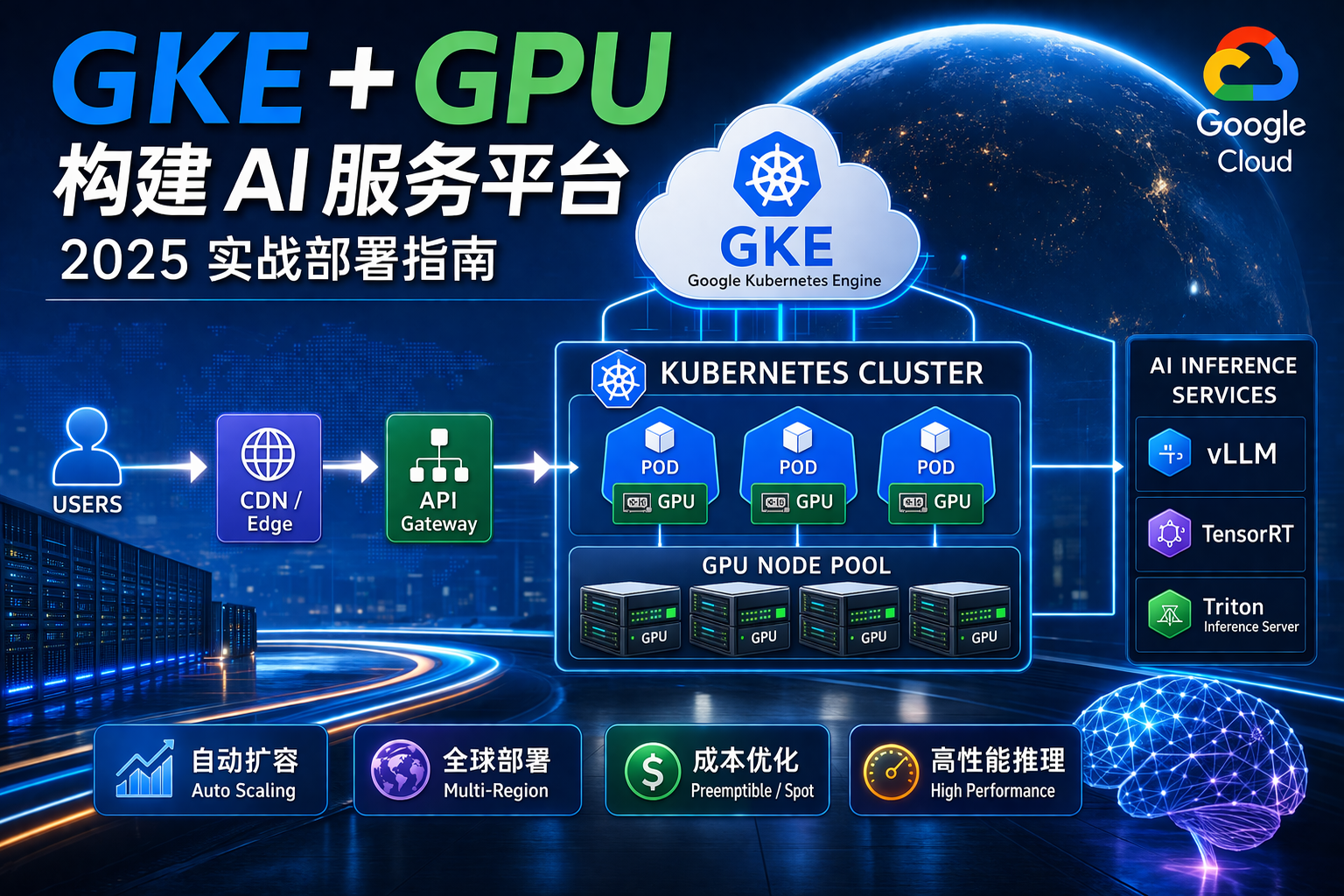
随着 AI SaaS 和大模型应用爆发,越来越多企业选择使用 Amazon EKS(Elastic Kubernetes Service) 来部署 LLM 推理服务,实现:
- 自动扩容
- GPU 调度
- 高可用架构
- 全球部署
但实际落地中,很多团队会遇到问题:
- GPU 无法正确调度
- 推理服务不稳定
- 成本过高
本文将从实战角度,完整讲解:
如何在 AWS EKS 上部署大模型推理服务(LLM Inference)
👉 在开始之前,建议先阅读:
一、为什么选择 EKS 部署 LLM?
相比自建 Kubernetes,EKS 优势明显:
✔ AWS 托管控制面
✔ 与 EC2 GPU 深度集成
✔ 支持 Auto Scaling
✔ 全球部署能力
二、EKS LLM 架构设计
典型架构如下:
用户 → API Gateway → EKS → GPU Pod → 推理服务
核心组件
1️⃣ EKS 集群
- 控制平面(AWS托管)
- Worker Node(EC2 GPU)
2️⃣ GPU 节点(EC2)
常见实例:
- g5(A10G)
- p4d(A100)
- p5(H100)
👉 官方:
https://aws.amazon.com/ec2/instance-types/#Accelerated_Computing
3️⃣ GPU Operator
👉 https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/
作用:
- 自动管理 GPU 驱动
- 提供 GPU 调度
4️⃣ 推理服务
推荐:
- vLLM
- TensorRT
- TGI
三、EKS 部署流程(实战)
第一步:创建 EKS 集群
使用:
- AWS Console
- eksctl
示例:
eksctl create cluster –name ai-llm-cluster
第二步:创建 GPU Node Group
eksctl create nodegroup \
–cluster ai-llm-cluster \
–instance-types g5.xlarge \
–nodes 2
第三步:安装 GPU Operator
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/gpu-operator/main/deployments/gpu-operator.yaml
第四步:部署推理服务
示例(vLLM):
docker run –gpus all -p 8000:8000 vllm/vllm
K8s Deployment:
resources:
limits:
nvidia.com/gpu: 1
四、EKS GPU 自动扩容(重点)
EKS 支持:
1️⃣ Cluster Autoscaler
自动扩容 GPU 节点
2️⃣ HPA(Pod 扩容)
根据:
- CPU
- GPU
- QPS
👉 推荐阅读:
五、生产环境优化(关键)
1️⃣ Spot GPU(成本优化)
👉 https://aws.amazon.com/ec2/spot/
优势:
✔ 降低 50%–70% 成本
2️⃣ 多区域部署
建议:
- 新加坡
- 东京
- 美西
3️⃣ 推理优化
推荐:
- TensorRT https://developer.nvidia.com/tensorrt
- vLLM
4️⃣ 缓存层
使用:
- Redis
- CDN
六、EKS + AI SaaS 架构(推荐)
用户
↓
Global Accelerator / CDN
↓
API Gateway
↓
EKS
↓
GPU Node Pool
↓
推理服务
👉 参考:
👉 《AI SaaS 平台基础设施搭建流程》
七、常见问题
GPU 不可用
原因:
- 没安装 GPU Operator
成本过高
原因:
- 没用 Spot
延迟高
原因:
- 单区域部署
八、最佳实践总结
✔ 使用 EKS + GPU
✔ 配置自动扩容
✔ 使用 Spot GPU
✔ 多区域部署
✔ API 网关接入
📌 总结
EKS 是目前部署 LLM 推理服务最成熟的方案之一。
适用于:
- AI SaaS
- AI 出海
- 企业 AI 平台
如果你希望:
- 快速搭建 AI 平台
- 优化 GPU 成本
- 实现全球部署
👉 推荐参考: