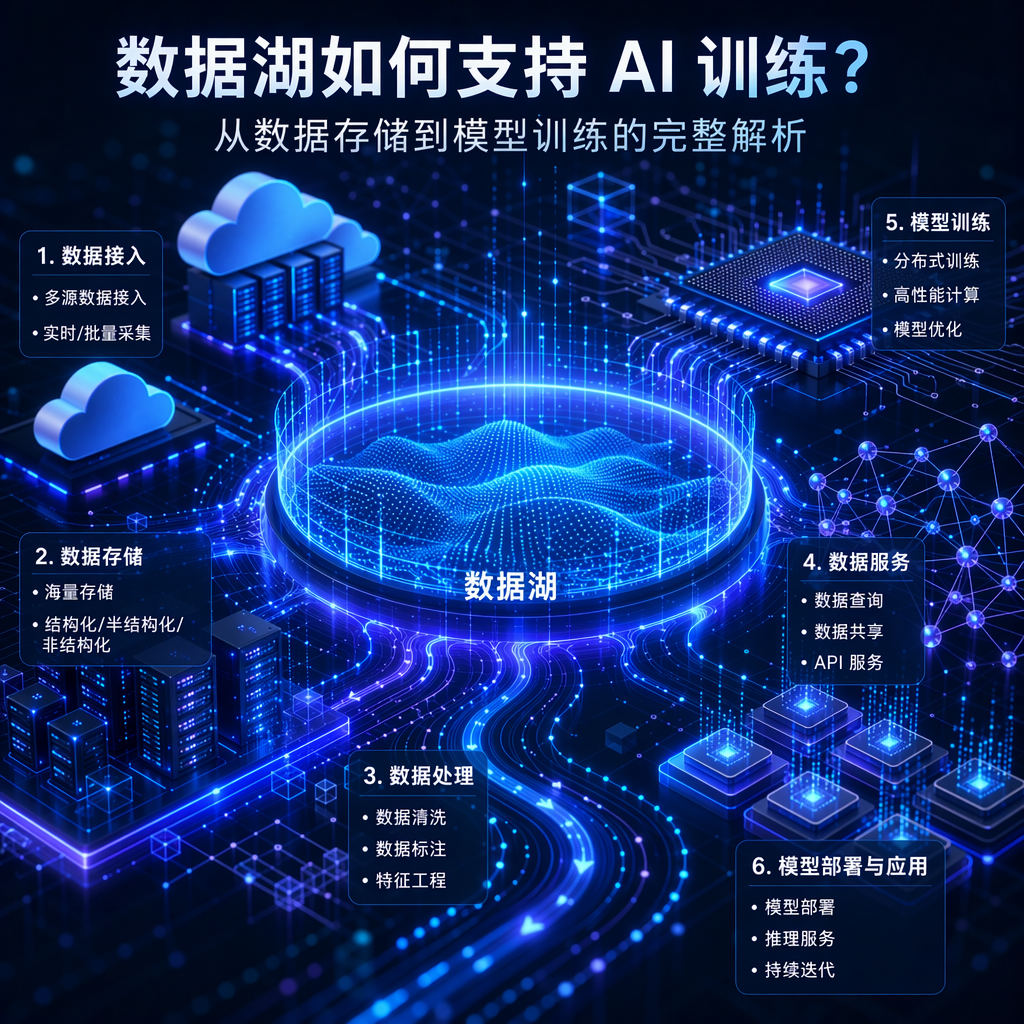
随着人工智能技术的快速发展,企业对数据的需求正在不断增长。无论是训练大语言模型、推荐算法、图像识别模型,还是构建智能客服、风险预测和自动化分析系统,AI 训练都离不开大量、高质量、多类型的数据。而数据湖,正是支撑 AI 训练的重要基础设施之一。
那么,数据湖如何支持 AI 训练?它为什么比传统数据仓库更适合 AI 场景?本文将从数据存储、数据处理、数据治理、特征工程和模型训练等角度进行详细解析。
什么是数据湖?
数据湖是一种集中式的数据存储架构,可以存储结构化、半结构化和非结构化数据。与传统数据仓库不同,数据湖通常采用“先存储,后建模”的方式,允许企业将原始数据直接保存下来,再根据业务和 AI 训练需求进行加工处理。
常见的数据类型包括:
- 结构化数据:数据库表、交易记录、用户信息等
- 半结构化数据:JSON、XML、日志文件、API 数据等
- 非结构化数据:图片、音频、视频、文档、网页内容等
对于 AI 训练来说,这种灵活的数据存储方式非常重要。因为 AI 模型往往需要从多种数据源中学习规律,而不是只依赖传统数据库中的表格数据。
数据湖为什么适合 AI 训练?
AI 训练的核心是数据。数据越丰富、质量越高、覆盖场景越全面,模型训练效果通常就越好。数据湖能够为 AI 训练提供统一的数据底座,让企业可以更高效地收集、管理和使用数据。
相比传统数据仓库,数据湖在 AI 训练中具备以下优势:
- 可以存储海量原始数据
- 支持多种数据格式
- 便于进行数据清洗和特征工程
- 支持批处理和实时数据处理
- 能与机器学习平台和 AI 框架集成
- 有利于数据治理、安全管理和权限控制
因此,数据湖不仅是数据存储平台,更是 AI 训练流程中的关键支撑系统。
一、数据湖为 AI 训练提供海量数据存储能力
AI 模型训练通常需要大量数据。例如,推荐系统需要用户行为数据,图像识别模型需要大量图片样本,自然语言处理模型需要文本语料,风控模型则需要交易、行为和历史风险数据。
数据湖可以低成本存储这些海量数据,并保留原始数据的完整性。企业可以将来自业务系统、日志系统、物联网设备、第三方平台和数据采集工具的数据统一汇入数据湖,形成一个可持续扩展的数据资源池。
这种集中式存储方式可以解决数据分散的问题,让 AI 团队不必在多个系统之间反复查找和搬运数据,从而提升模型训练效率。
二、数据湖支持多类型数据融合
AI 训练往往不是只依赖单一数据源,而是需要融合多维度数据。例如,一个智能推荐模型可能同时需要:
- 用户基础信息
- 用户浏览行为
- 商品信息
- 点击和购买记录
- 搜索关键词
- 图片和文本内容
- 实时行为日志
数据湖可以同时接收并存储这些不同类型的数据,为 AI 模型提供更完整的训练样本。通过数据融合,模型可以学习到更丰富的特征,从而提升预测准确率和业务效果。
例如,在智能客服场景中,企业可以将历史聊天记录、用户画像、工单数据、知识库文档和语音转写文本统一存放到数据湖中,再用于训练问答模型或意图识别模型。
三、数据湖提升数据清洗和预处理效率
原始数据通常无法直接用于 AI 训练,因为它可能存在缺失值、重复数据、异常数据、格式不统一、标签不准确等问题。因此,在模型训练之前,必须进行数据清洗和预处理。
数据湖可以配合数据处理引擎,对原始数据进行统一处理,例如:
- 去除重复数据
- 补全缺失字段
- 过滤异常值
- 标准化数据格式
- 提取有效字段
- 生成训练样本
- 构建标签数据
通过数据湖,企业可以建立标准化的数据处理流程,保证 AI 训练数据的稳定性和一致性。这样不仅能提高模型训练质量,也能减少后续模型调优的成本。
四、数据湖支持特征工程
特征工程是机器学习和 AI 训练中的关键环节。所谓特征,就是模型用于学习和判断的输入变量。例如,在用户流失预测模型中,用户登录频率、购买次数、最近一次访问时间、客服投诉次数等都可以成为特征。
数据湖能够整合不同来源的数据,为特征工程提供丰富的数据基础。数据科学家可以从数据湖中提取、组合和转换数据,构建更有价值的模型特征。
例如:
- 将用户历史行为转化为活跃度特征
- 将交易记录转化为消费能力特征
- 将文本内容转化为语义特征
- 将时间序列数据转化为趋势特征
- 将设备日志转化为故障预测特征
高质量的特征可以显著提升 AI 模型的表现,而数据湖正是支撑特征工程的重要平台。
五、数据湖支持 AI 训练数据版本管理
在 AI 项目中,数据版本管理非常重要。因为模型训练结果不仅与算法有关,也与训练数据版本密切相关。如果数据发生变化,而没有记录版本信息,就很难复现之前的模型结果。
数据湖可以帮助企业保留不同阶段的数据版本,包括原始数据、清洗后的数据、标注数据、训练集、验证集和测试集等。这样,AI 团队可以清楚知道某个模型使用了哪一批数据进行训练。
数据版本管理的价值包括:
- 支持模型训练结果复现
- 便于对比不同数据集的训练效果
- 降低数据误用风险
- 支持模型审计和合规要求
- 提高 AI 项目的可管理性
对于企业级 AI 应用来说,数据可追溯性是非常重要的,而数据湖能够为这一点提供基础保障。
六、数据湖提升 AI 训练流程自动化
现代 AI 训练通常需要结合数据管道、机器学习平台和自动化工作流。数据湖可以作为 AI 训练流程中的核心数据入口,与数据处理工具、特征平台、模型训练平台和模型部署系统进行集成。
一个典型流程如下:
- 数据从业务系统进入数据湖
- 数据湖保存原始数据
- 数据处理任务进行清洗和转换
- 特征工程生成训练特征
- 训练平台读取数据进行模型训练
- 模型评估后进入部署环节
- 新数据持续回流,支持模型迭代
通过这种方式,企业可以构建持续迭代的 AI 训练体系,让模型不断学习新的数据,提升业务适应能力。
七、数据湖帮助提升数据治理和安全性
AI 训练不仅需要数据量,更需要数据质量和数据合规。尤其是在金融、医疗、政务、电商等行业,数据安全、隐私保护和权限控制非常关键。
数据湖可以结合数据治理体系,实现:
- 数据目录管理
- 数据血缘追踪
- 数据质量检测
- 权限分级控制
- 敏感数据脱敏
- 数据访问审计
- 合规管理
这意味着企业不仅可以使用数据进行 AI 训练,还能确保数据使用过程安全、合规、可追踪。
例如,在训练用户画像模型时,企业可以对手机号、身份证号、地址等敏感信息进行脱敏处理,避免隐私泄露风险。
八、数据湖与 AI 训练平台如何结合?
数据湖本身并不直接训练模型,而是为 AI 训练平台提供数据支持。它通常会与机器学习框架和计算平台结合使用,例如 Spark、TensorFlow、PyTorch、Flink、Kubeflow、MLflow 等。
数据湖负责存储和管理数据,计算平台负责处理和训练模型,机器学习平台负责实验管理、模型评估和部署。三者结合后,可以形成完整的 AI 工程化体系。
这种架构能够帮助企业实现从数据采集、数据加工、模型训练到模型上线的完整闭环。
数据湖支持 AI 训练的典型应用场景
数据湖在 AI 训练中的应用非常广泛,常见场景包括:
1. 智能推荐系统
电商、内容平台和短视频平台可以利用数据湖存储用户行为、商品信息、点击记录和浏览数据,用于训练推荐算法,提升用户转化率和停留时间。
2. 风险控制模型
金融机构可以将交易数据、设备信息、用户行为和历史风险记录存入数据湖,用于训练欺诈检测和信用评估模型。
3. 智能客服和大语言模型
企业可以将客服对话、知识库文档、工单记录和用户反馈存入数据湖,用于训练智能问答、意图识别和文本生成模型。
4. 工业预测性维护
制造企业可以通过数据湖存储设备传感器数据、故障日志和维修记录,用于训练设备故障预测模型。
5. 医疗影像分析
医疗机构可以将影像数据、诊断记录和病历文本存入数据湖,用于训练疾病识别和辅助诊断模型。
企业建设 AI 数据湖需要注意什么?
虽然数据湖能够很好地支持 AI 训练,但如果缺乏规划,也可能变成“数据沼泽”。企业在建设 AI 数据湖时,需要重点关注以下几点:
- 明确 AI 训练目标和业务场景
- 建立统一的数据标准
- 做好数据质量管理
- 规划数据权限和安全策略
- 建立数据目录和血缘关系
- 支持数据版本管理
- 与机器学习平台深度集成
- 持续优化数据处理流程
只有把数据湖建设与 AI 应用目标结合起来,才能真正发挥数据价值。
总结:数据湖是 AI 训练的重要数据底座
数据湖如何支持 AI 训练?简单来说,数据湖通过统一存储海量数据、融合多类型数据、支持数据清洗、特征工程、数据版本管理和安全治理,为 AI 模型训练提供稳定、灵活、可扩展的数据基础。
对于希望发展人工智能能力的企业来说,数据湖不仅是大数据架构的一部分,更是 AI 训练和智能化转型的核心基础设施。只有建立高质量的数据湖,企业才能更高效地训练模型、优化算法,并将 AI 能力真正应用到业务场景中。